First of all, a few words about these two platforms.
In schooX each user has a set of collected articles and each article is described by user assigned tags. The superset of all articles' tags forms the user's tag cloud. In graph theory terms, a user is a node and his tags are the node's edges. We will put Gephi to layout all user nodes and their respective edges, but first we have to get the dataset.
The Process
This first part of the article will detail steps 1,2,3 of the process.
- Extract the model in csv format (user-tags)
- Parse schooX user profiles with cURL
- Store html profile pages locally.
- Grep or XPath user tag clouds from the htmls.
- Create the csv file and import into Gephi.
- Perform cluster analysis and graph drawing layout algorithms.
- Export and Gimp the final image with different fx.
Final Result
Before detailing the process, some images of the final result.
We can identify user concentration around some topics such as social media, software development, medical sciences etc. Interesting...the startup's dataset has already started getting in shape forming communities around some hot topics. On to the images (available in flickr too):
 |
| schooX Network Graph |
 |
| schooX Network Graph with Labels |
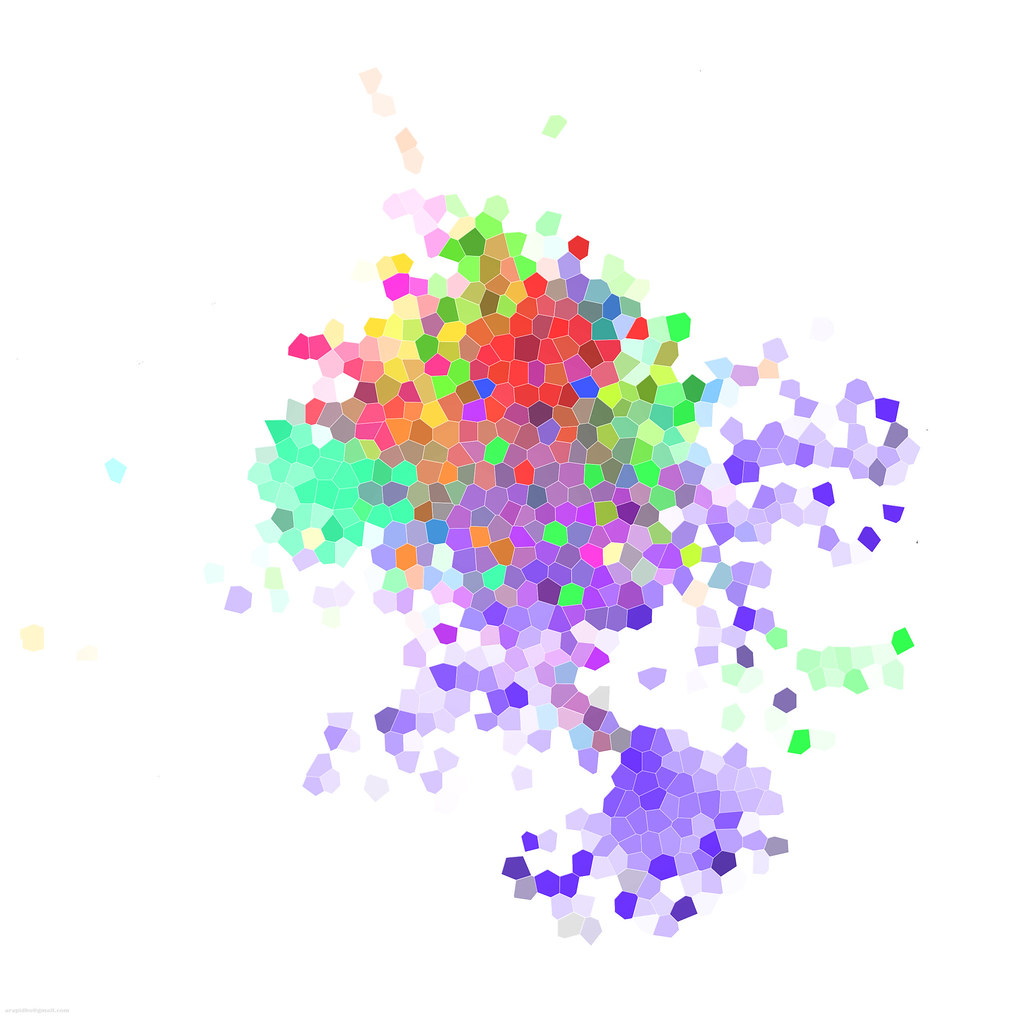 |
| Glass Clustering Effect |
 |
| Network Painting - qualifies as an abstract poster? |
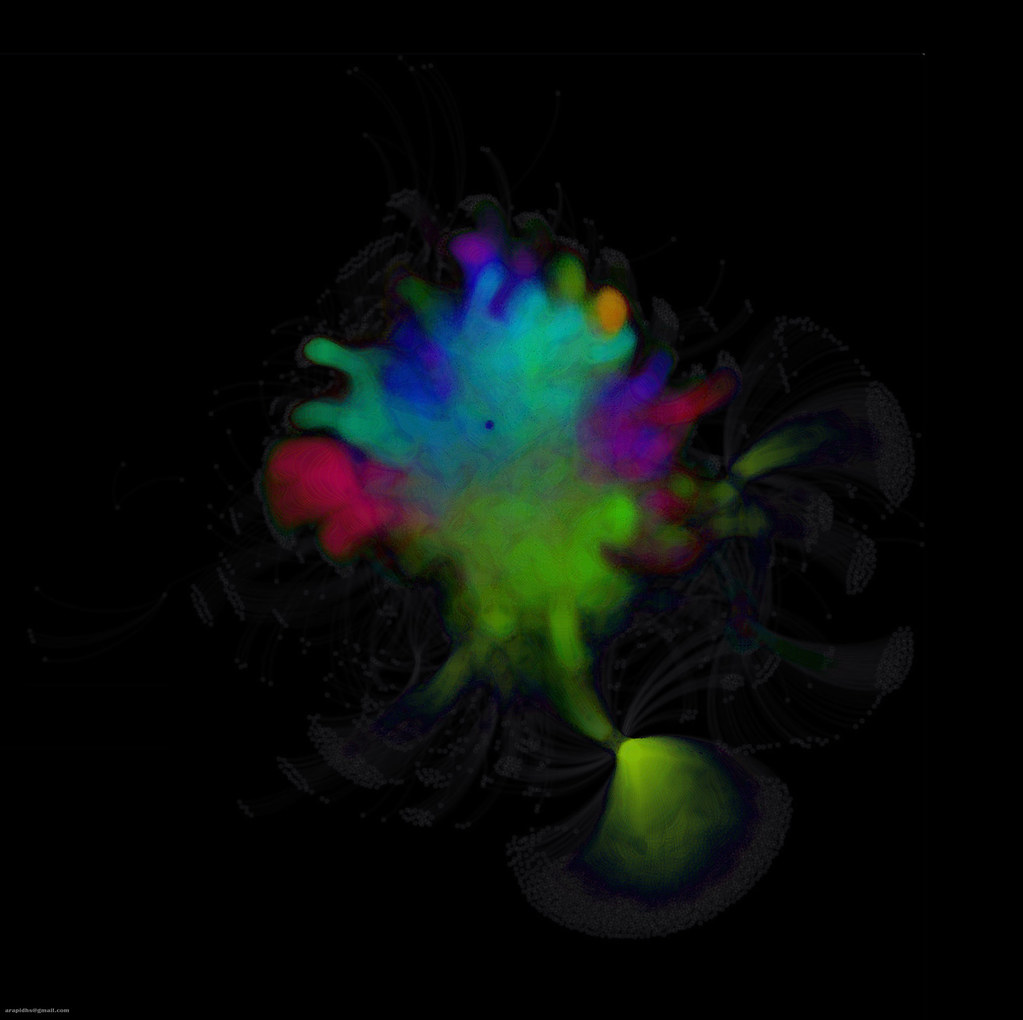 |
| Dark Neon Abstract |
Parsing data, assessing the model
Since we haven't got direct access to any dataset or database we can only do the...unthinkable :) Create a schooX account, parse all users' public tag-clouds and create our model in csv format. Each row of the csv file will contain two columns and will be imported to Gephi:
- tag name
- unique user name
schooX' entry point is:
http://www.schoox.com/login/index.php
User profile pages containing the user's tag cloud follow this URL pattern:
http://www.schoox.com/user/7969/tag-cloud/
For example 7969 is my user id. After some trial and error we can find the last user id since an error comes up in place of a user profile page simply because there is no user with such an id.
The cURL (see-url) command
We will use curl (see-url) to login to schooX and store the login cookie, parse all user's profile pages and store them locally as html files. Later, we will extract from pages the tags for each user.
Login to schooX and store cookie:
Starting from id 1 to the user max id we consecutively execute curl ,(see-url), to parse all user profiles:
Our tmp local directory now stores all user profiles and tag clouds in separate html pages. Each html page is named after the corresponding user's id.
Have a look:

In part 2 we will parse these pages with Tidy to generate a csv model file to import into Gephi.
The format of the csv will be something like with each row representing an edge of the network:
coefficient,Charalampos Arapidis
http://www.schoox.com/login/index.php
User profile pages containing the user's tag cloud follow this URL pattern:
http://www.schoox.com/user/7969/tag-cloud/
For example 7969 is my user id. After some trial and error we can find the last user id since an error comes up in place of a user profile page simply because there is no user with such an id.
The cURL (see-url) command
We will use curl (see-url) to login to schooX and store the login cookie, parse all user's profile pages and store them locally as html files. Later, we will extract from pages the tags for each user.
Login to schooX and store cookie:
curl --cookie-jar cjar --data 'username=arapidhs@gmail.com' --data 'password=********' --output /dev/null http://www.schoox.com/login/index.phpStarting from id 1 to the user max id we consecutively execute curl ,(see-url), to parse all user profiles:
#!/bin/bash
for i in {1..200000}
do
curl --cookie cjar --output /home/arapidhs/tmp/i.html http://www.schoox.com/user/i/tag-cloud/
done
Our tmp local directory now stores all user profiles and tag clouds in separate html pages. Each html page is named after the corresponding user's id.
Have a look:

In part 2 we will parse these pages with Tidy to generate a csv model file to import into Gephi.
The format of the csv will be something like with each row representing an edge of the network:
coefficient,Charalampos Arapidis
paok,Charalampos Arapidis
neural,Charalampos Arapidis
desktop,Charalampos Arapidis
minimal,Charalampos Arapidis
analog,Charalampos Arapidis
Fourier,Charalampos Arapidis
Java,Charalampos Arapidis
visualization,Charalampos Arapidis
software,Charalampos Arapidis
subversion,Charalampos Arapidis
social,Charalampos Arapidis
processing,Charalampos Arapidis
See you soon, and happy collecting!


